从YouTube视频中获取文本记录感觉像是一个聪明的学习技巧。你得到所有口头文字的布局,准备好复习,而无需重新观看整个视频。但这种方法有一个巨大的盲点:它完全忽略了屏幕上发生的事情。
一段文字墙无法显示正在绘制的复杂图表。它无法捕捉演示者突出显示的确切代码行。它无法传达正在演示的微妙的身体技术。视频学习存在记忆问题,而仅仅依靠文本会使情况变得更糟。
为什么你的YouTube视频文本记录遗漏了一半的内容
视频的设计是为了展示,而不仅仅是讲述。当你剥离视觉层并仅依赖文本记录时,你正在制造一个巨大的信息鸿沟。对于技术教程、科学解释或任何视觉效果可能比叙述更重要的内容来说,尤其如此。

纯文本笔记的问题
想象一下尝试学习一项新的软件功能。你更喜欢文本描述还是实际工作流程的屏幕录像?文本记录给你“是什么”,但遗漏了只有在屏幕上才能看到的“如何”和“为什么”。这导致了常见的挫折:
- **信息不完整:**未大声说出的关键屏幕操作会丢失。
- **缺乏背景:**没有视觉效果来锚定,图表的描述变得抽象。
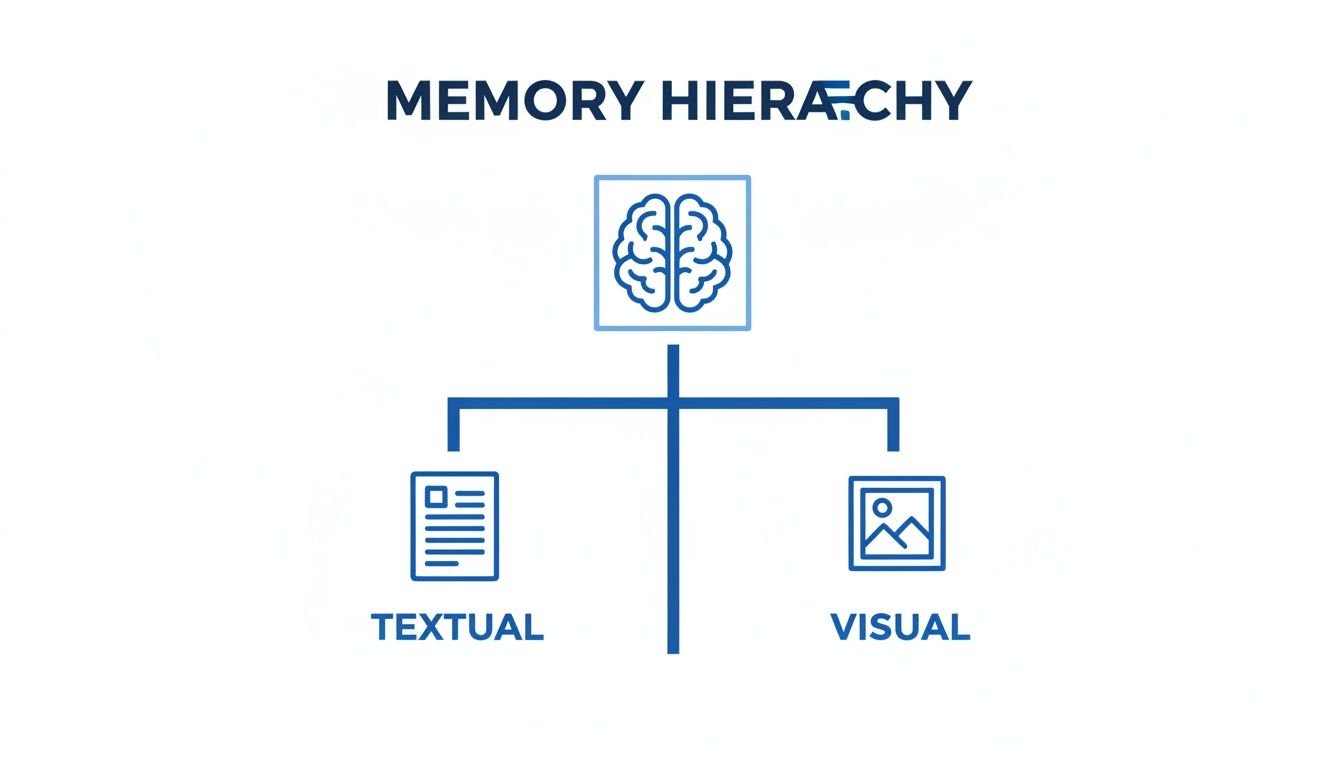
- **记忆力差:**我们的大脑被设计为将文字与图像联系起来。正如我们之前探讨过的,这是视频学习的核心问题——仅仅是文本很难回忆起来。
文本记录可能会告诉你演示者指向“图表中最重要的部分”,但它无法向你展示那部分是什么。以后尝试复习这样的笔记只是猜测。
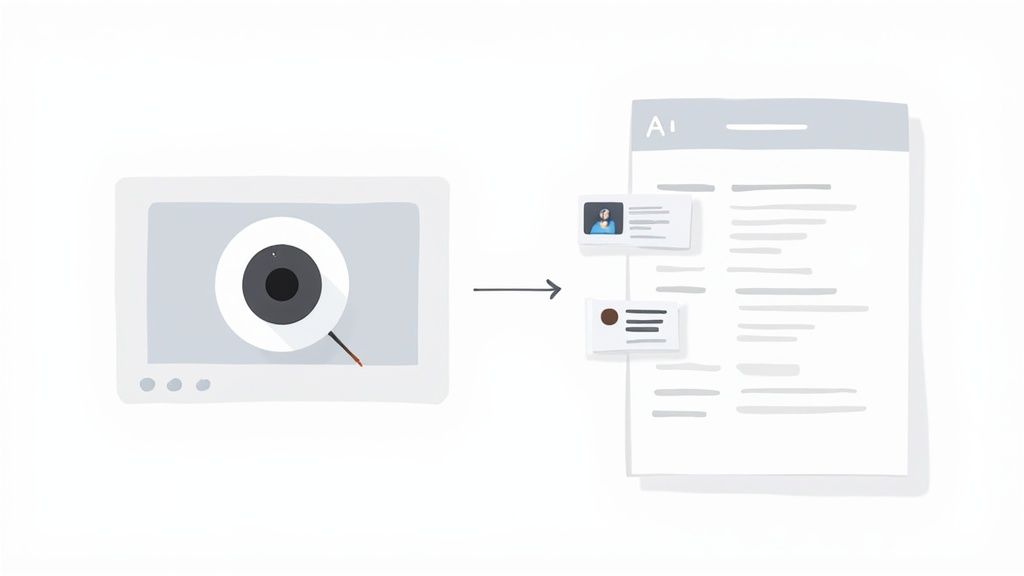
这就是为什么仅解析视频文本记录的工具从根本上受到限制。它们对你所看到的内容视而不见。相比之下,像HoverNotes这样的工具实际上逐帧分析视频,就像人一样观看它。这使其能够捕获重要图表、代码片段和关键时刻的时间戳屏幕截图,并将它们嵌入到你的笔记中。这保留了关键的视觉背景,使视频学习有效。
文本记录工具 vs. 逐帧视频分析
当你从YouTube视频中提取信息时,你使用的工具分为两类。这种差异是创建以后可以实际记住和使用的笔记的关键。
一方面,你有基于文本记录的工具。它们快速而简单——它们连接到YouTube并提取自动生成的字幕。但这里有一个问题:它们从根本上是盲目的。它们只处理音频,这意味着它们错过了屏幕上实际发生的一切。所有关键的图表、代码片段和现场演示对它们来说都是完全不可见的。