Как превратить PDF в полезные заметки в формате Markdown | HoverNotes
General26 декабря 2025 г.
Как превратить PDF в полезные заметки в формате Markdown
Откройте для себя лучшие методы преобразования PDF в Markdown. Наше руководство охватывает мощные инструменты, обработку сложных файлов и интеграцию заметок в ваш рабочий процесс.
Автор HoverNotes Team•12 мин чтения
Преобразование PDF в Markdown — это не техническая рутина; это акт освобождения. Оно выводит ваши документы из статичного, непоискового формата и превращает их в гибкие, текстовые файлы, которые вы действительно можете использовать для обучения и исследований.
PDF-файлы отлично подходят для сохранения окончательного макета, например, резюме или опубликованного отчета. Но для создания базы знаний они — тупик. Вы не можете легко искать по папке с PDF-файлами, связывать идеи между документами или извлекать цитату без мучительной борьбы с копированием и вставкой.
Markdown, с другой стороны, — это просто текст. Он легкий, универсальный и готов к действию.
#Почему простой текст лучше заблокированного файла
Представьте себе библиотеку, где каждая книга запечатана в пленку. Вы можете видеть обложки, но не можете открыть их, чтобы связать идеи внутри. Это и есть папка с PDF-файлами. Преобразование их в Markdown — все равно что распаковать каждую книгу.
Эта плотная научная статья или неуклюжее техническое руководство внезапно становятся живой частью вашей базы знаний.
Вот почему это важно для серьезно настроенных учащихся:
Вы действительно владеете этим: Файлы Markdown не заблокированы в проприетарном программном обеспечении, таком как Adobe Acrobat. Это просто текст. Вы можете открыть их сотнями бесплатных приложений сегодня, и вы все еще сможете открыть их через 50 лет.
Мгновенный поиск: Когда-нибудь пытались найти одно конкретное предложение в папке из 100 PDF-файлов? Это кошмар. С Markdown вы можете использовать общесистемный поиск или простые инструменты командной строки, чтобы найти что угодно во всей вашей библиотеке за секунды.
Хорошо сочетается с другими: Markdown — это родной язык современных инструментов для управления знаниями, таких как Obsidian, Logseq и Notion. После преобразования ваши документы можно связывать, тегировать и вплетать в более крупную сеть идей.
Защитите свои знания на будущее: Технологии меняются, но простой текст вечен. Это самый стабильный и надежный формат для хранения информации, которую вы хотите сохранить. Больше не нужно беспокоиться о проблемах совместимости файлов.
Делая этот переход, вы превращаете статичные архивы в динамичные активы. Это основной принцип эффективного программного обеспечения для управления персональными знаниями. Ваша библиотека перестает быть цифровым кладбищем и становится взаимосвязанной, живой сетью идей.
Не все PDF-файлы одинаковы. Онлайн-инструмент, который идеально справляется с текстовым документом, испортит многоколоночную научную статью с таблицами и диаграммами. Правильный выбор подхода сэкономит вам часы ручной чистки.
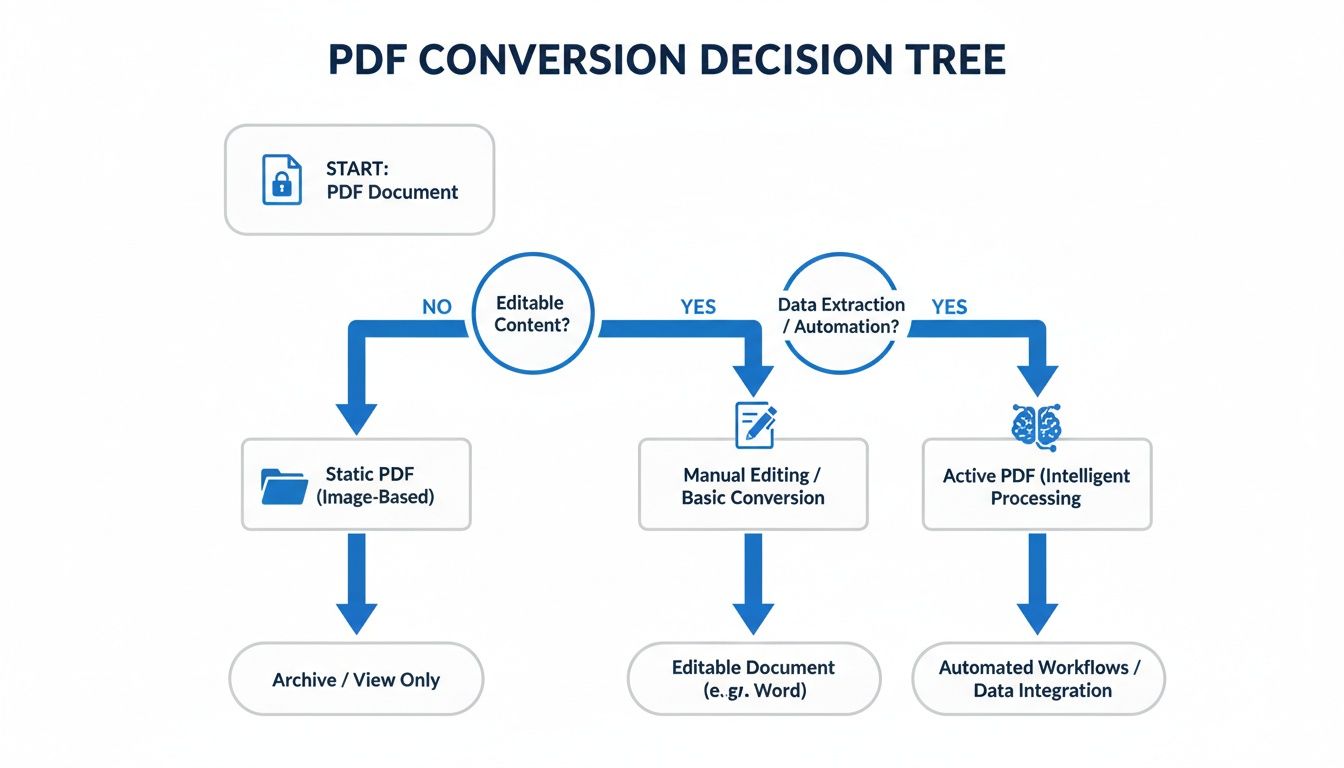
Выбор сводится к двум вещам: типу вашего PDF-файла и тому, что вам нужно с ним делать. Это быстрое дерево решений поможет вам подобрать правильную стратегию для вашего документа.
Блок-схема доходит до сути: вы делаете быстрое, одноразовое преобразование или пытаетесь перенести сложный документ в активную систему знаний, такую как Obsidian?
Ваши варианты превращения PDF в Markdown делятся на три категории, каждая из которых имеет свои компромиссы между скоростью, точностью и конфиденциальностью.
Онлайн-конвертеры: Это веб-сайты, куда вы загружаете PDF, а они выдают файл Markdown. Они быстрые и не требуют установки, что делает их отличным выбором для быстрых, неконфиденциальных документов. Огромный минус? Вы загружаете свои данные на сторонний сервер. Это недопустимо для чего-либо личного или конфиденциального. Качество также может быть лотереей при работе со сложными макетами.
Инструменты командной строки (например, Pandoc): Для тех, кто ценит контроль, автоматизацию и полную конфиденциальность, инструменты командной строки — лучший выбор. Инструмент вроде Pandoc работает полностью на вашем локальном компьютере, что означает, что ваши файлы никогда его не покидают. Он дает вам точный контроль над выводом, обрабатывая все, от цитат до сложных таблиц. Требуется небольшая настройка, но повторяемые, высококачественные результаты того стоят для всех, кто регулярно работает с документами.
Решения на основе OCR: Что, если ваш "PDF" — это просто набор изображений, как отсканированный учебник? Стандартные конвертеры полностью провалятся. Здесь на помощь приходит оптическое распознавание символов (OCR). Инструменты OCR сканируют изображения, определяют символы и восстанавливают текст. Современный OCR удивительно хорош с четкими, напечатанными документами. Это самый интенсивный метод, но единственный, который работает для PDF-файлов на основе изображений.
Чтобы сделать выбор более ясным, вот краткое сравнение.
Эта таблица разбирает самые распространенные методы, выделяя их сильные и слабые стороны, а также идеальные случаи использования.
Метод
Лучше всего для
Плюсы
Минусы
Онлайн-конвертеры
Быстрых, простых, неконфиденциальных документов.
Чрезвычайно быстро, не требует настройки, очень прост в использовании.
Серьезные риски для конфиденциальности, нестабильное качество, проблемы со сложными макетами.
Командная строка (Pandoc)
Опытных пользователей, разработчиков и всех, кому нужна конфиденциальность и контроль.
Работает локально (конфиденциально), высокая точность, возможность написания скриптов для автоматизации.
Требует установки и изучения основных команд.
Инструменты OCR
Отсканированных документов, изображений текста и невыделяемых PDF.
Единственный способ извлечь текст из изображений.
Может быть медленным, точность зависит от качества изображения, часто требует доработки.
Нет единого "лучшего" инструмента — есть только лучший инструмент для конкретной задачи.
Выбор правильного инструмента — это первый шаг к созданию цифровой библиотеки, которой вы действительно можете пользоваться, основной принцип многих лучших приложений для заметок для студентов. Согласование метода с документом с самого начала гарантирует гораздо более чистое преобразование.
#Использование инструментов командной строки, таких как Pandoc
Для тех, кто ценит конфиденциальность, контроль и воспроизводимые результаты, инструменты командной строки являются лучшим вариантом для преобразования PDF в Markdown. Онлайн-конвертеры быстры, но они означают загрузку ваших файлов на чужой сервер. С помощью такого инструмента, как Pandoc, весь процесс остается на вашем компьютере.
Этот подход идеально подходит для разработчиков, ученых и всех, кому нужен надежный офлайн-рабочий процесс. Это метод «сделай один раз, сделай правильно», который можно автоматизировать для пакетной обработки целых папок с документами. Хотя настройка занимает несколько минут, точность и безопасность, которые вы получаете, непревзойденны.
Pandoc не зря называют швейцарским ножом для конвертации документов. Это мощный инструмент с открытым исходным кодом, который может читать и записывать десятки форматов.
После установки основная команда для преобразования PDF в Markdown проста. Откройте терминал и выполните:
pandoc my-document.pdf -o my-document.md
Эта одна строка указывает Pandoc взять my-document.pdf в качестве входного файла и создать файл Markdown с именем my-document.md. Теперь у вас есть чистая текстовая версия вашего исходного файла, готовая для вашего приложения для заметок.
Сообщество разработчиков открытого исходного кода всегда расширяет границы возможного с локальной обработкой. Новые инструменты, такие как Marker, могут обрабатывать сложные многоязычные документы со скоростью в 4 раза выше, чем многие облачные парсеры, сохраняя при этом высокое качество изображений и таблиц.
Настоящая сила Pandoc заключается в его гибкости. Вы можете добавлять «флаги» к основной команде для обработки сложных документов с изображениями, таблицами и цитатами, которые сбивают с толку более простые инструменты. Для более сложных настроек ознакомьтесь с нашими руководствами по настройке продвинутых рабочих процессов.
Вот несколько практических примеров:
Обработка таблиц: если преобразование таблиц по умолчанию выглядит беспорядочно, вы можете указать более надежный движок синтаксического анализа с помощью флага, такого как --pdf-engine.
Извлечение изображений: Pandoc может попытаться извлечь изображения из PDF и сохранить их в отдельной папке.
Управление цитатами: для научных статей он может анализировать библиографии и правильно форматировать их в Markdown, избавляя вас от огромной головной боли.
Собрав воедино несколько простых команд, вы можете создать полностью приватную и автоматизированную систему для превращения всей вашей PDF-библиотеки в поисковую, взаимосвязанную базу знаний.
Именно здесь большинство автоматических конвертеров pdf в markdown терпят неудачу.
Простой текстовый документ — это одно. Но реальные PDF-файлы — научные статьи, технические руководства или отчеты — полны изображений, сложных таблиц и фрагментов кода. Простой инструмент преобразования превратит их в нечитаемую мешанину.
Корень проблемы в том, что PDF-файлы не понимают структуру контента; они заботятся только о визуальном размещении. Для PDF изображение не «встроено» в текст — это просто визуальный объект, нарисованный в определенных координатах. Это та же проблема, с которой вы сталкиваетесь при обучении по видео: простой транскрипт упускает весь важный контекст из диаграммы или блока кода на экране. Делать заметки по видео сложно, потому что вы постоянно делаете паузы, чтобы зафиксировать эти визуальные детали.
Чтобы получить пригодный для использования файл Markdown, вам нужен план для каждого типа сложного контента. Обычно это означает сочетание автоматического извлечения с некоторой ручной доработкой.
Для изображений: Ваш лучший выбор — двухэтапный процесс. Сначала используйте инструмент для работы с PDF, чтобы извлечь все изображения в отдельную папку. Затем, по мере доработки файла Markdown, ссылайтесь на них с помощью стандартного синтаксиса ``. Это похоже на то, как вы могли бы захватывать и организовывать визуальные материалы из видео, процесс, который мы описываем в нашем руководстве о том, как делать скриншоты из YouTube.
Для таблиц: Таблицы особенно сложны. Мощный инструмент командной строки, такой как Pandoc, хорошо справляется с угадыванием структуры, но вам следует ожидать, что придется вручную исправлять некоторые символы-разделители | и выравнивание столбцов. Для невероятно сложных таблиц часто быстрее просто сделать скриншот и вставить его как изображение.
Для блоков кода: Большинство конвертеров выдадут код как простой, неформатированный текст, теряя все отступы и подсветку синтаксиса. Решение — вручную обернуть извлеченный текст в блоки кода Markdown (используя три обратных апострофа ) и добавить идентификатор языка (например, python).
Лучшие решения на базе ИИ теперь заявляют о более чем 95% точности для сложных документов, что является огромным скачком по сравнению с 50-60% у бесплатных онлайн-инструментов, которые портят заголовки и таблицы. Такая производительность достигается за счет обучения на тысячах сложных, реальных PDF-файлов. Вы можете увидеть отличный обзор различных конвертеров PDF в Markdown на blazedocs.io.
Идеальное, однократное преобразование для сложного PDF все еще редкость. Всегда выделяйте время на ручную доработку, чтобы убедиться, что конечный документ Markdown чистый, правильный и действительно полезный.
#Вплетение ваших новых заметок в ваше хранилище Obsidian
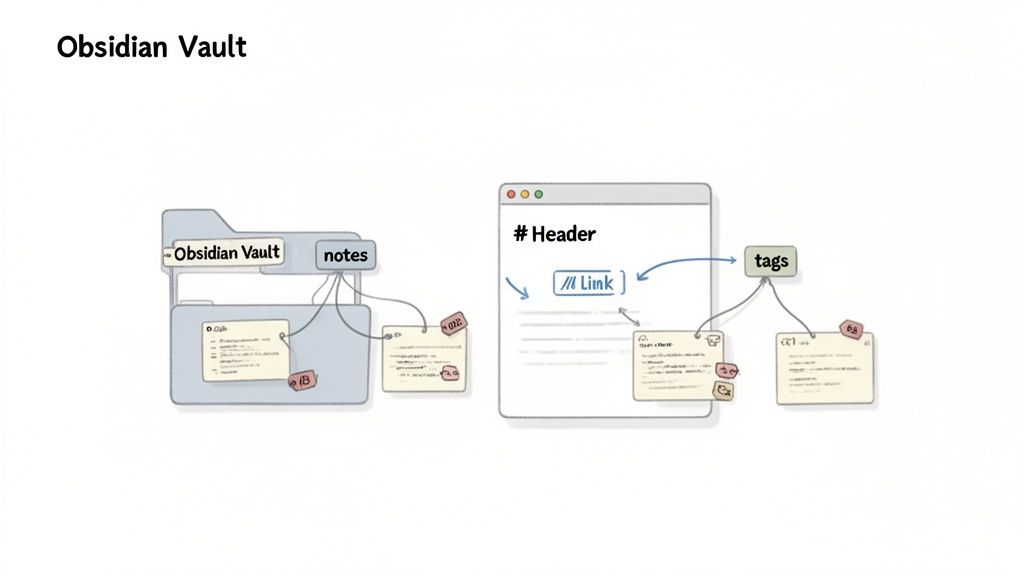
Вы успешно извлекли содержимое из PDF и преобразовали его в чистый Markdown. Но папка, полная несвязанных файлов .md, — это не база знаний, а просто цифровой хлам. Настоящая ценность появляется, когда вы превращаете эти файлы в связанную, доступную для поиска часть вашего мозга в таком инструменте, как Obsidian.
Сначала просто перетащите ваши новые файлы Markdown в папку вашего хранилища Obsidian. Поскольку Obsidian построен на основе простых текстовых файлов, они появятся немедленно. Этот локальный подход является ключевым; ваши знания остаются на вашем компьютере, где им и место.
Попав в ваше хранилище, необработанный текст нуждается в структуре, чтобы стать полезным. Цель состоит в том, чтобы создать связи, которые отражают ваш образ мышления.
Хорошо работает простой трехэтапный рабочий процесс:
Создайте исходную заметку: Для каждого документа создайте центральную заметку (например, [[Статья - Будущее ИИ.md]]). Она становится домом для метаданных, таких как автор, дата публикации и краткое резюме, почему вы ее сохранили. Все ваши подробные заметки затем ссылаются на этот единственный источник.
Используйте теги для широких категорий: Добавьте теги, такие как #ИИ, #исследование или #проект-гидра. Теги предназначены для организации высокого уровня, позволяя вам мгновенно находить все, что связано с темой, независимо от того, где находятся файлы в вашем хранилище.
Связывайте идеи с помощью WikiLinks: Именно здесь ваша граф знаний оживает. При просмотре преобразованного текста оборачивайте ключевые понятия в синтаксис Obsidian [[]]. Это простое действие превращает статический документ в активный узел в вашей сети идей.
Вы владеете файлами. Перемещайте их, создавайте резервные копии, используйте grep для поиска — это просто Markdown. Такой уровень владения — причина, по которой так много серьезных учеников строят свои базы знаний на локальных инструментах.
Этот процесс превращает базовое преобразование pdf в markdown в мощный рабочий процесс для построения знаний. И если вы извлекаете информацию из видео, некоторые инструменты могут автоматизировать это для вас. Например, HoverNotes интегрируется с Obsidian, чтобы сохранять заметки с временными метками и мультимедийным контентом непосредственно в виде файлов Markdown в ваше хранилище. Заметки принадлежат вам с момента их создания.
Связывая, тегируя и структурируя, вы не просто храните информацию. Вы создаете устойчивую, взаимосвязанную библиотеку, которая со временем становится все более ценной.
#Часто задаваемые вопросы (и их решения) по преобразованию PDF в Markdown
Даже с лучшими инструментами преобразование PDF в Markdown может иметь свои особенности. Вот самые распространенные проблемы и способы их решения.
#Могу ли я преобразовать отсканированный PDF с рукописным текстом?
Да, но для этого требуется инструмент с мощным движком оптического распознавания символов (OCR). Обычный PDF-конвертер видит рукописную страницу как одно большое изображение.
Успех преобразования зависит от того, насколько четкий почерк. Специализированные приложения OCR дают наилучший результат, но вам следует запланировать некоторую ручную доработку. Для отсканированных документов с четким напечатанным текстом современный OCR удивительно точен.
#Почему мои таблицы выглядят как полный беспорядок?
Это самая неприятная часть преобразования PDF. Проблема не в конвертере, а в PDF. PDF-файлы не хранят таблицы в виде аккуратных строк и столбцов. Они просто хранят визуальное расположение линий и текста, размещенных в определенных координатах. Большинство конвертеров просто угадывают структуру, поэтому они так часто ошибаются.
Инструменты на базе ИИ намного лучше справляются с анализом визуального макета и правильным угадыванием структуры таблицы.
Инструменты командной строки, такие как Pandoc, иногда могут творить чудеса, но вам может потребоваться настроить команды, чтобы получить правильный результат.
Честно говоря, для действительно сложных таблиц самым быстрым решением часто бывает просто сделать скриншот таблицы и вставить его как изображение в ваш Markdown.
#Какой лучший бесплатный инструмент для быстрого преобразования?
Для одного простого текстового документа бесплатный онлайн-конвертер быстр, потому что ничего не нужно устанавливать. Компромисс — конфиденциальность: вы загружаете свой файл на чужой сервер.
Если вам нужны надежные, высококачественные и полностью конфиденциальные преобразования, лучшим бесплатным вариантом является локальный инструмент, такой как Pandoc. Настройка занимает немного времени, но он работает полностью на вашем собственном компьютере. Ваши документы никогда не покидают ваш компьютер.
Как только вы освоитесь, вы получите полный контроль, лучшие результаты и даже сможете писать простые скрипты для пакетного преобразования десятков файлов одновременно. Для всех, кто делает это регулярно, первоначальные временные затраты быстро окупаются.
Если вы часто конвертируете много документов для улучшения своего учебного процесса, возможно, вы также сталкиваетесь с трудностями при запоминании информации из видео. HoverNotes — это расширение для Chrome, которое смотрит видео вместе с вами, генерирует заметки с помощью ИИ и сохраняет их в формате Markdown прямо в вашу файловую систему. Вы можете попробовать его бесплатно — 20 минут кредитов ИИ, кредитная карта не требуется.
Создайте мощный воркфлоу для заметок по YouTube в Obsidian. Узнайте, как фиксировать, организовывать и связывать видео-знания, чтобы действительно запоминать то, что смотрите.
Узнайте, как программное обеспечение для управления личными знаниями может организовать ваше обучение по видео. Изучите практические рабочие процессы для студентов, использующих PKM-инструменты, такие как Obsidian.
Перестаньте забывать то, что смотрите. Узнайте, как превратить любое видео с YouTube в заметки и создать доступную для поиска долгосрочную базу знаний, которой вы действительно владеете.