Watch Once, Reference Forever.
© 2026 HoverNotes. All rights reserved.
English 한국어 中文(简体) 日本語 Italiano Português Русский Deutsch Español Tiếng Việt Français PDFを実用的なMarkdownノートに変換する方法 | HoverNotes
PDFをMarkdownに変換することは、単なる技術的な作業ではなく、解放の行為です。それは、文書を静的で検索不可能な形式から解放し、学習や研究に実際に使用できる柔軟なプレーンテキストファイルに変えます。
PDFは、履歴書や公開レポートのような最終的なレイアウトを保持するのに優れています。しかし、知識を構築するためには行き止まりです。PDFのフォルダ全体を簡単に検索したり、文書間のアイデアを接続したり、イライラするコピー&ペーストの戦いなしに引用を抜き出したりすることはできません。
一方、Markdownは単なるテキストです。軽量で普遍的であり、すぐに使用できます。
# すべての本がシュリンクラップされている図書館を想像してみてください。表紙は見えますが、中のアイデアを接続するために開くことはできません。それがPDFのフォルダです。それらをMarkdownに変換することは、すべての本を解き放つようなものです。
その密度の高い学術論文や扱いにくい技術マニュアルが、突然あなたの知識ベースの生きた一部になります。
これが真剣な学習者にとって重要な理由を以下に示します。
あなたはそれを実際に所有している: Markdownファイルは、Adobe Acrobatのような独自のソフトウェアにロックされていません。それらは単なるテキストです。今日、何百もの無料アプリで開くことができ、50年後も開くことができます。即座の検索性: 100個のPDFのフォルダの中から特定の1文を見つけようとしたことがありますか?それは悪夢です。Markdownを使用すると、システム全体の検索やシンプルなコマンドラインツールを使用して、ライブラリ全体から数秒で何でも見つけることができます。
他のツールとの連携: Markdownは、Obsidian、Logseq、Notionなどの最新の知識ツールのネイティブ言語です。変換後、文書はリンクされ、タグ付けされ、より大きなアイデアのウェブに織り込まれることができます。
知識の将来性: テクノロジーは変化しますが、プレーンテキストは永遠です。それは、保持したい情報を保存するための最も安定した信頼性の高い形式です。ファイル互換性の問題を心配する必要はもうありません。この切り替えを行うことで、静的なアーカイブを動的な資産に変えています。これは、効果的な個人知識管理ソフトウェア の背後にある核となる原則です。あなたのライブラリはデジタル墓場であることをやめ、相互接続された生きたアイデアのネットワークになり始めます。
すべてのPDFが同じように作成されているわけではありません。テキストのみの文書を完璧に処理するオンラインツールは、テーブルやチャートでいっぱいの多段組の学術論文を台無しにするでしょう。適切なアプローチを選択することで、手作業によるクリーンアップの時間を何時間も節約できます。
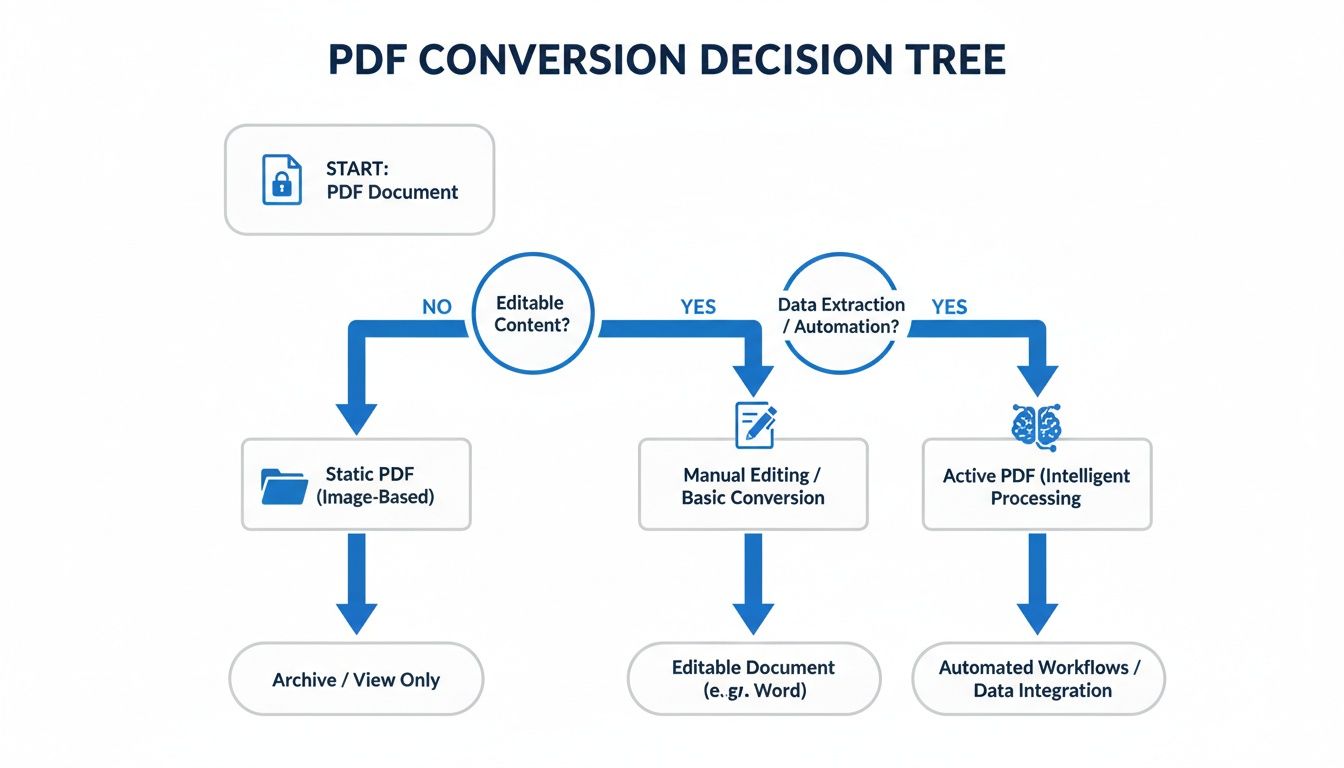
選択は2つのことに帰着します。あなたが持っているPDFの種類と、それを使って何をしたいかです。この簡単な意思決定ツリーは、あなたの文書を適切な戦略に合わせるのに役立ちます。
フローチャートは核心に迫っています。あなたは迅速な1回限りの変換を行っていますか、それとも複雑な文書をObsidianのようなアクティブな知識システムに取り込もうとしていますか?
PDFをMarkdownに変換するためのオプションは、速度、精度、プライバシーのトレードオフがある3つのカテゴリのいずれかに分類されます。
オンラインコンバーター: これらは、PDFをアップロードするとMarkdownファイルが返されるウェブサイトです。高速でインストール不要なため、迅速で機密性の低い文書に最適です。大きな問題は、データをサードパーティのサーバーにアップロードすることです。これは、個人的または機密性の高いものにとっては問題外です。複雑なレイアウトでは品質もギャンブルになる可能性があります。
コマンドラインツール(Pandocなど): コントロール、自動化、および完全なプライバシーを重視する人にとって、コマンドラインツールが最適です。Pandoc のようなツールは完全にローカルマシンで実行されるため、ファイルがコンピューターから離れることはありません。引用から複雑なテーブルまで、すべてを処理する出力に対して正確な制御を提供します。セットアップには少し時間がかかりますが、文書を定期的に扱う人にとっては、繰り返し可能で高品質な結果が得られる価値があります。
OCRベースのソリューション: あなたの「PDF」がスキャンされた教科書のような画像のコレクションである場合はどうでしょうか?標準のコンバーターは完全に失敗します。ここで**光学文字認識(OCR)**が登場します。OCRツールは画像をスキャンし、文字を識別し、テキストを再構築します。最新のOCRは、鮮明でタイプされた文書に対して驚くほど優れています。これは最も集中的な方法ですが、画像ベースのPDFに機能する唯一の方法です。
選択をより明確にするために、簡単な比較を以下に示します。
この表は、最も一般的な方法を分類し、その長所、短所、および理想的な使用例を強調しています。
「最高の」ツールは1つだけではありません。仕事に最適なツールがあるだけです。
適切なツールを選択することは、実際に使用できるデジタルライブラリを構築するための最初のステップであり、学生向けの最高のノート作成アプリ の多くが持つ核となる原則です。最初から文書に合った方法を選択することで、はるかにクリーンな変換が保証されます。
プライバシー、コントロール、および再現可能な結果を重視する人にとって、コマンドラインツールはPDFをMarkdownに変換するための最良のオプションです。オンラインコンバーターは高速ですが、ファイルを他の誰かのサーバーにアップロードすることを意味します。Pandoc
VIDEO
このアプローチは、開発者、学者、および堅実なオフラインワークフローを必要とするすべての人に最適です。これは、文書のフォルダ全体をバッチ処理するためにスクリプト化できる「一度やったら正しくやる」方法です。セットアップには数分かかりますが、得られる精度とセキュリティは比類のないものです。
Pandocは、文書変換のスイスアーミーナイフと呼ばれることがよくあります。それは、数十の形式を読み書きできる強力なオープンソースツールです。
インストール後、PDFをMarkdownに変換する基本的なコマンドはシンプルです。ターミナルを開いてこれを実行します。
pandoc my-document.pdf -o my-document.md
この1行は、Pandocにmy-document.pdfを入力として受け取り、my-document.mdというMarkdownファイルを作成するように指示します。これで、元のファイルのクリーンなテキストベースのバージョンが、ノートアプリですぐに使用できるようになります。
テーブルの処理: デフォルトのテーブル変換が乱雑に見える場合は、--pdf-engineのようなフラグでより堅牢な解析エンジンを指定できます。画像の抽出: PandocはPDFから画像を抽出し、別のフォルダに保存しようとすることができます。引用の管理: 学術論文の場合、参考文献を解析し、Markdownで正しくフォーマットできるため、大きな手間を省くことができます。 いくつかの簡単なコマンドを組み合わせることで、PDFライブラリ全体を検索可能で相互接続された知識ベースに変えるための、完全にプライベートで自動化されたシステムを構築できます。
これは、ほとんどの自動pdf to markdownコンバーターが失敗する場所です。
単純なテキスト文書は1つのことです。しかし、実際のPDF(学術論文、技術マニュアル、レポート)には、画像、複雑なテーブル、コードスニペットが満載です。基本的な変換ツールは、これらを読めない混乱に変えてしまいます。
問題の根源は、PDFがコンテンツ構造を理解していないことです。視覚的な配置のみを気にします。PDFにとって、画像はテキストに「埋め込まれている」のではなく、特定の座標に描画された視覚オブジェクトにすぎません。これは、ビデオから学習するときに直面するのと同じ課題です。単純なトランスクリプトでは、画面上の図やコードブロックからの重要なコンテキストがすべて失われます。ビデオからメモを取るのは、これらの視覚的な詳細をキャプチャするために常に一時停止する必要があるため、困難です。
使用可能なMarkdownファイルを取得するには、各種類の複雑なコンテンツに対する計画が必要です。これは通常、自動抽出と手動クリーンアップを組み合わせることを意味します。
画像の場合: 最善の方法は2段階のプロセスです。まず、PDFツールを使用してすべての画像を別のフォルダに抽出します。次に、Markdownファイルをクリーンアップするときに、標準の``構文でそれらにリンクします。これは、YouTubeからスクリーンキャプチャする方法 に関するガイドで説明しているように、ビデオからビジュアルをキャプチャして整理する方法に似ています。
テーブルの場合: テーブルは非常に扱いにくいことで知られています。Pandoc のような強力なコマンドラインツールは、構造をうまく推測しますが、パイプ|文字と列の配置の一部を手動で修正する必要があることを期待してください。信じられないほど複雑なテーブルの場合、スクリーンショットを撮って画像として埋め込む方が速いことがよくあります。
コードブロックの場合: ほとんどのコンバーターは、コードをプレーンな未フォーマットのテキストとして出力し、すべてのインデントと構文のハイライトを失います。修正方法は、抽出されたテキストをMarkdownのフェンス付きコードブロック(3つのバックティック``を使用)で手動で囲み、言語識別子(pythonなど)を追加することです。
複雑なPDFの完璧なワンクリック変換はまだまれです。最終的なMarkdown文書がクリーンで正確で、実際に役立つことを確認するために、常に手動での整理に時間を割いてください。
# PDFからコンテンツを抽出し、クリーンなMarkdownに変換することに成功しました。しかし、切断された.mdファイルでいっぱいのフォルダは知識ベースではなく、単なるデジタルジャンクドロワーです。本当の価値は、それらのファイルをObsidianのようなツール内で、あなたの脳の接続された検索可能な部分に変えるときに生まれます。
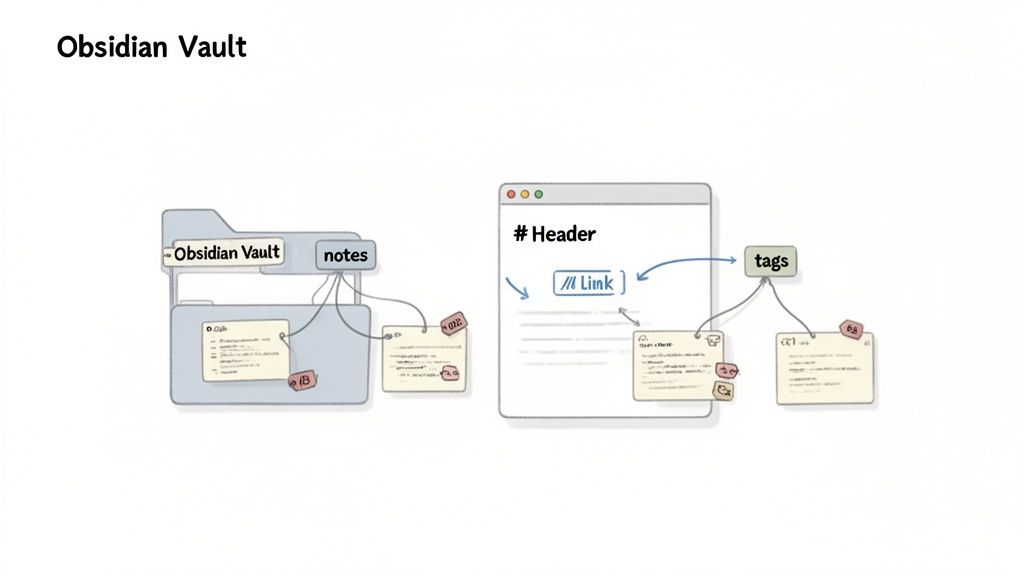
まず、新しいMarkdownファイルをObsidian vaultフォルダにドラッグアンドドロップするだけです。Obsidianはプレーンテキストファイルに基づいて構築されているため、すぐに表示されます。このローカルファーストのアプローチが重要です。あなたの知識は、あるべき場所に、あなたのマシン上に留まります。
vault内に入ると、生のテキストは有用になるために構造を必要とします。目標は、あなたの考え方を反映する接続を作成することです。
シンプルな3段階のワークフローがうまく機能します。
ソースノートを作成する: すべての文書について、中央のノート(例:[[Paper - The Future of AI.md]])を作成します。これは、著者、発行日、保存した理由の簡単な要約などのメタデータのホームになります。すべての詳細なノートは、この単一のソースにリンクされます。
広範なカテゴリのタグ付け: #AI、#research、#project-hydraなどのタグを追加します。タグは高レベルの整理用であり、ファイルがvaultのどこにあっても、トピックに関連するすべてを即座に表示できます。
Wikiリンクでアイデアを接続する: ここであなたの知識グラフが生き生きとします。変換されたテキストをレビューするときに、主要な概念をObsidianの[[]]構文で囲みます。このシンプルな行為により、静的な文書がアイデアのウェブのアクティブなノードに変わります。
あなたはファイルを所有しています。移動したり、バックアップしたり、grepしたりできます。それらは単なるMarkdownです。このレベルの所有権が、多くの真剣な学習者がローカルファーストツールで知識ベースを構築する理由です。
このプロセスは、基本的なpdf to markdown変換を、知識を構築するための強力なワークフローに変えます。そして、ビデオから洞察を抽出している場合、一部のツールはこれを自動化できます。たとえば、HoverNotesはObsidianと統合 して、タイムスタンプ付きのメディアリッチなノートをMarkdownファイルとしてvaultに直接保存します。ノートは作成された瞬間からあなたのものです。
リンク、タグ付け、構造化によって、情報を保存するだけでなく、時間の経過とともに価値が高まる、回復力のある相互接続されたライブラリを構築しています。
# 最高のツールを使用しても、PDFをMarkdownに変換するといくつかの癖がある場合があります。最も一般的な問題とその修正方法を次に示します。
はい、しかしこれには強力な**光学文字認識(OCR)**エンジンを備えたツールが必要です。通常のPDFコンバーターは、手書きのページを単なる大きな画像として認識します。
変換の成功は、手書きの鮮明さに依存します。専門のOCRアプリが最善の策を提供しますが、手動でのクリーンアップを計画する必要があります。鮮明でタイプされたテキストを含むスキャンされた文書の場合、最新のOCRは驚くほど正確です。
これはPDF変換で最もイライラする部分です。問題はコンバーターではなく、PDFです。PDFはテーブルをきれいな行と列として保存しません。線とテキストの視覚的な配置を特定の座標に保存するだけです。ほとんどのコンバーターは構造を推測しているだけなので、間違えることがよくあります。
AI搭載ツール は、視覚的なレイアウトを見てテーブル構造を正しく推測するのに優れています。Pandocのようなコマンドラインツール は奇跡を起こすこともありますが、正しく機能させるにはコマンドを微調整する必要があるかもしれません。正直なところ、本当に複雑なテーブルの場合、最も速い修正方法は、テーブルのスクリーンショットを撮って Markdownに画像として埋め込むことであることがよくあります。
単一のシンプルでテキストのみの文書の場合、無料のオンラインコンバーターはインストールするものがないため高速です。トレードオフはプライバシーです。ファイルを他の誰かのサーバーにアップロードすることになります。
信頼性の高い、高品質で完全にプライベートな変換が必要な場合は、Pandoc のようなローカルツールが最適な無料オプションです。セットアップには少し時間がかかりますが、完全に自分のマシンで実行されます。文書がコンピューターから離れることはありません。
一度慣れてしまえば、完全なコントロール、より良い結果が得られ、数十のファイルを一度にバッチ変換するための簡単なスクリプトを作成することもできます。これを定期的に行う人にとっては、初期の投資はすぐに元が取れます。
General January 23, 2026
Obsidian YouTubeノートのための強力なワークフローを構築しましょう。動画から得た知識を効率的に記録、整理、リンクさせ、実際に記憶に残す方法を学びます。
General December 6, 2025
個人知識管理ソフトウェアが動画学習をどのように整理できるかを発見しましょう。Obsidianなどの PKM ツールを使用する学生向けの実践的なワークフローを探ります。
General November 28, 2025
見た動画を忘れるのはもうやめましょう。YouTube動画をノートに変換し、自分だけの検索可能で長期的なナレッジベースを構築する方法を学びましょう。