動画と視覚学習は完璧な組み合わせだと思いますよね。でも、チュートリアルを見て完全に理解したと感じたのに、後になると...何も残っていない。そんな経験はありませんか?
これはよくある記憶定着の問題です。動画を受動的に見ているだけでは、脳が戦略なしに情報を吸収しようとするため、認知的過負荷につながりがちです。情報を定着させるには、受動的な視聴を能動的な学習に変える必要があります。それには、ノートの取り方に構造化されたビジュアルアプローチが必要です。
#動画を見るだけでは不十分な理由

これは視覚型学習者にとって典型的なパラドックスです。解説動画を再生し、すべてのステップを追い、「なるほど!」という瞬間を得る。しかし翌日には、詳細がぼやけている。この「コンテンツ健忘症」は受動的な消費の典型的な症状です。脳に見ること、聞くこと、処理することを同時に求めているのですが、これは何かを深く学ぶには非効率的な方法です。
能動的に関わる方法がなければ、最も重要な部分—ビジュアルコンテキスト—を失ってしまいます。
#失われるビジュアルコンテキストの問題
例えば、YouTubeのチュートリアルで新しいコーディング関数を学んでいるとします。講師がロジックを説明しながら、正確な構文が画面に表示されます。見てうなずきますが、実際にはそれをしていません。自分でコードを書こうとすると、どのような構造だったか思い出せません。
キャプチャ
それは、ビジュアル自体—コードスニペット、図表、画面上のデモンストレーション—が記憶の中の何にもアンカーされていなかったからです。テキストの文字起こしに頼るのはさらに悪く、画面上のコードを完全に失ってしまいます。これについてより深く知りたい方は、YouTubeの動画文字起こしを取得して学習に活用する方法をご覧ください。
核心的な問題は、見ることと学ぶことは同じではないということです。真の記憶定着は、教材と対話すること—重要なビジュアルをキャプチャし、説明されている概念と結びつけること—から生まれます。
スクリーンショットを撮るために常に一時停止する従来の方法は不便です。集中力を粉々にし、バラバラの画像でごちゃごちゃしたフォルダが残るだけです。動画学習を本当に機能させるには、ビジュアル情報をコンテキストの中でキャプチャするよりスマートな方法が必要です。
効果的な学習は、適切な情報をキャプチャすることから始まります。しかし視覚型学習者にとって、テキストだけでは不十分です。実際の図表、画面上のコード、ステップバイステップのデモンストレーションが必要です。問題は、動画を見ながら手動でノートを取るのが難しいことです。常に動画を一時停止し、スクリーンショットを撮り、ウィンドウを切り替え、どこかに貼り付けるのは面倒で、学習の流れから完全に引き離されてしまいます。
はるかに良いワークフローは、ビジュアル証拠をキャプチャし、それが表示された瞬間にノートに直接埋め込むことです。これにより、即座にコンテキストが提供され、「散らばったスクリーンショット」問題が解決されます。Screen Shot 2024-10-26 at 11.45.12 AM.pngという名前のランダムなファイルの代わりに、書いた考えのすぐ横にビジュアルアンカーが得られます。
ここで専用ツールが大きな違いを生みます。例えば、**HoverNotesは動画と一緒に視聴し、AIノートを生成し、Markdownとしてファイルシステムに直接保存するChrome拡張機能です。**文字起こしのみを解析するツールとは異なり、HoverNotesは動画をフレームごとに視聴し、画面に実際に表示されているもの—図表、コード、デモンストレーションを含む—をキャプチャします。
目標はシンプルです:見たものを、見た瞬間に、摩擦なくキャプチャすること。これにより、ノートは話されたことの弱い要約ではなく、ビジュアルレッスンの真の反映になります。
このアプローチは、ノート取りを面倒な作業から学び方のシームレスな一部に変えます。視覚的に重要なものを正確にキャプチャし、学習教材が完全であることを保証します。画面キャプチャテクニックについてより深く知りたい方は、YouTube動画からスクリーンショットを撮るガイドをご覧ください。
#フルスクリーンショットを超えて:必要な部分だけを切り取る
常に動画フレーム全体が必要なわけではありません。時には、特定の図表1つ、コードのブロック1つ、混雑したスライドの数式1つだけが必要なこともあります。
そんな時は動画の特定の領域を切り取りましょう。このテクニックにより、ノートがクリーンになり、最も重要なビジュアル情報だけに焦点を当てることができます。これはObsidianユーザーにとって大きなメリットです。ノートが.mdファイルとして直接保存されるため、これらの埋め込み画像スニペットはVaultにネイティブに表示され、永遠に所有できる豊かで検索可能なビジュアルナレッジベースが作成されます。
動画から重要なビジュアルを取得することは素晴らしい第一歩ですが、それは仕事の半分に過ぎません。それらのスクリーンショットとノートがフォルダに放置されていると、曖昧な記憶よりもましとは言えません。本当の学習は、脳が全体像を見ることができるようにビジュアルを整理するときに起こります。
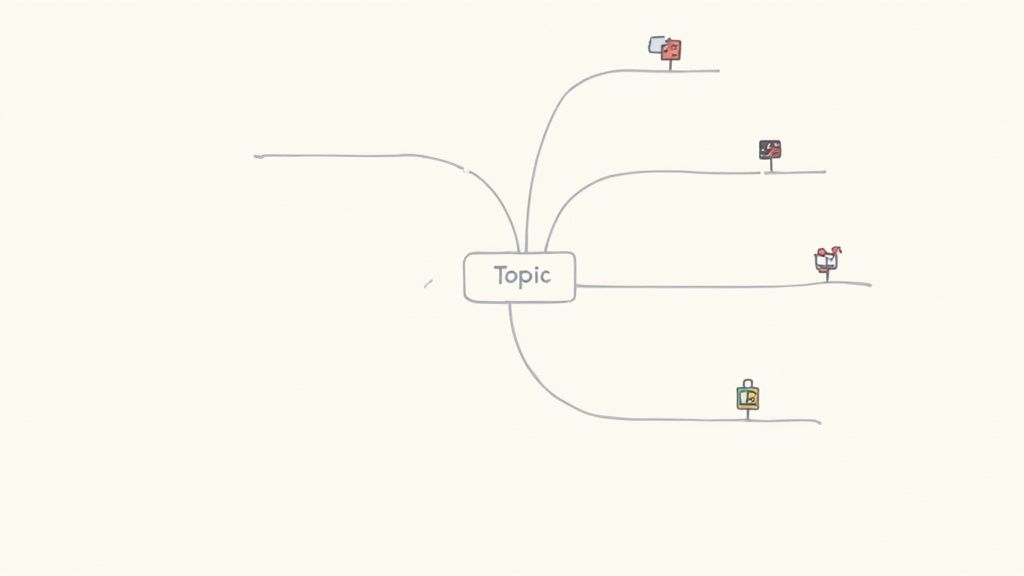
ここでマインドマップとデジタルキャンバスが効果を発揮します。視覚型学習者にとって、それらは私たちの心が自然にアイデアをつなげる方法—直線的ではなく空間的に—を反映しています。テキストの壁に迷い込む代わりに、トピックの鳥瞰図が得られます。
Obsidianに組み込まれているようなデジタルキャンバスを、個人的な無限のホワイトボードと考えてください。ここで強力なビジュアルスタディガイドを組み立てることができます。
シンプルに始めましょう:動画のメイントピックの中央ノードを作成します。そこから、キーコンセプトで分岐し、キャプチャしたスクリーンショットを各アイデアのビジュアルアンカーとしてドロップします。
プロセス自体が、異なる情報がどのように関連しているかを批判的に考えることを強制します。例えば、関数の構文のスクリーンショットから、その基礎となるロジックを説明する図表に直接線を引くことができます。
ビジュアルノートを空間的に配置することで、情報を保存するだけでなく、ナビゲートできる理解のマップを構築しています。各ビジュアルは特定の概念のランドマークになります。
これは単に「気分が良い」方法ではありません—証拠に裏付けられています。研究によると、情報が関連するビジュアルと組み合わされると、3日後の記憶保持率は約**65%に跳ね上がる可能性があります。比較として、テキストや話し言葉だけでは10-20%**の記憶保持率にとどまることが多いです。視覚学習に関する研究を自分で確認できます。
ビジュアルノート取りツールとキャンバスを組み合わせると、ワークフローがピッタリとはまります。例えば、HoverNotesのようなツールを使うと、埋め込まれたタイムスタンプ付きスクリーンショットが完備されたMarkdownファイルを、Obsidian Canvasに直接ドラッグできます。
各ノートは即座に移動可能なカードになり、他のアイデアと接続する準備が整います。
結果として得られるのは、動的で生きたスタディガイドです。マインドマップ上の概念がぼやけて感じたら、スクリーンショットをクリックするだけです。すべてのスクリーンショットにはクリック可能なタイムスタンプが含まれているため、ワンクリックで動画のその正確な瞬間に戻り、すばやく復習できます。これは複数の動画からの情報を1つのまとまったマップに統合する効果的な方法です。
本当の学習は消費ではありません。それは関与です。動画講義の「再生」を押すだけでは、情報が流れてくるのに任せて、いくつかの滴が定着することを願っているようなものです。見たもののほとんどを忘れることが保証される戦略です。
持続する知識を構築するには、教材を能動的に処理する必要があります。
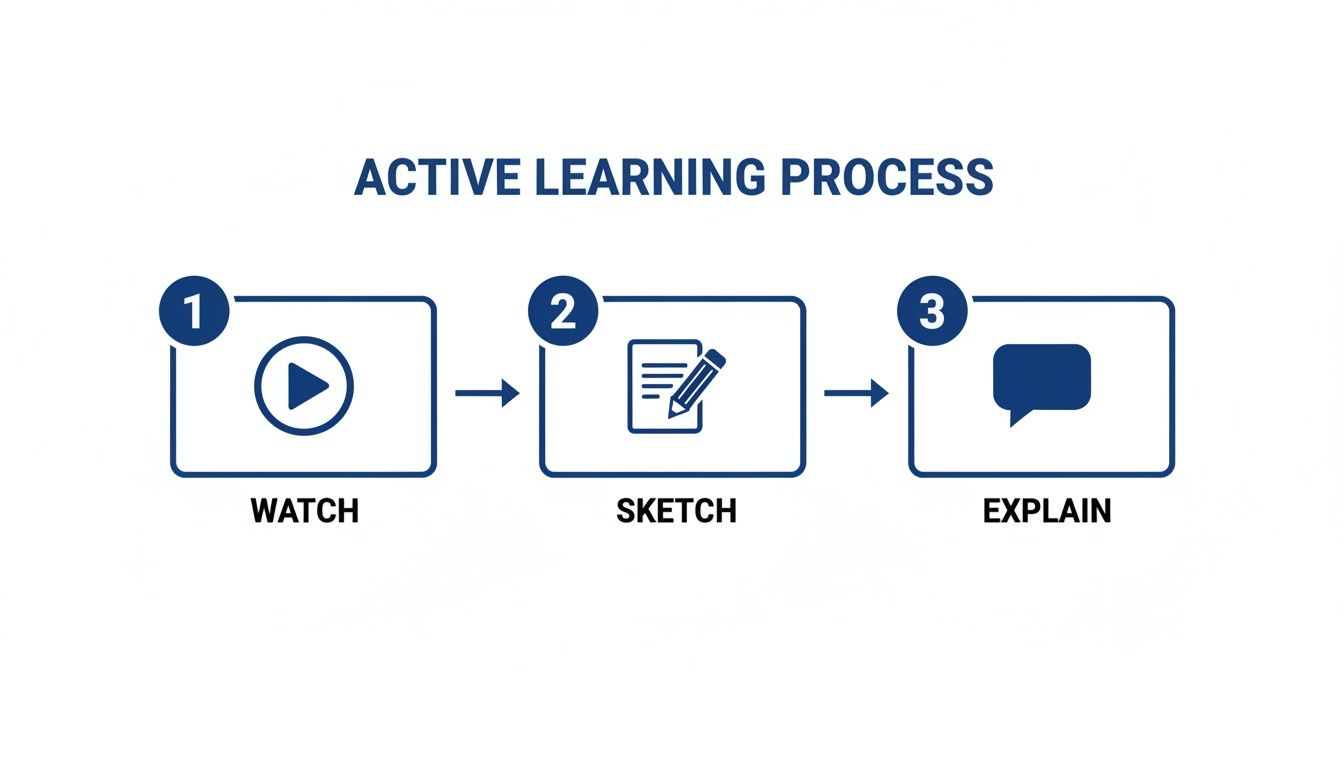
これを行う強力な方法の1つは、Feynmanテクニックのビジュアル版です。動画の短いセグメント(おそらく1、2分だけ)を見てから、一時停止します。巻き戻さずに、ペンを取り、学んだばかりの概念をスケッチしてみてください。フローチャートを描けますか?プロセスを図示できますか?
この記憶からビジュアルを再現しようとするシンプルな行為が、脳に情報を受動的に観察するのではなく処理することを強制します。
このアプローチは認知科学に裏付けられています。二重符号化理論と呼ばれ、アイデアはシンプルです:脳はビジュアル情報(スクリーンショットなど)と自分自身の言語的または書面による説明(ノートなど)を組み合わせると、より強い記憶を形成します。
動画から図表をキャプチャし、その横に自分の要約を書くと、同じアイデアへの2つの別々の精神的経路を構築しています。その冗長性により、試験中に情報をはるかに思い出しやすくなります。
ここで適切なツールを持つことが大きな違いを生みます。ノートとコンテンツを並べて配置する気を散らさない動画モードは、「後で取り組む」のではなく、リアルタイムでアイデアを要約してつなげることを促します。
学習は動画を見ることにあるのではなく、ビジュアル情報を処理し自分で再説明する行為にあります。観客から能動的な参加者にシフトする必要があります。
データがこれを裏付けています。視覚学習に関する研究によると、図解付きの講義から学ぶ学生は、テキストだけを読む学生と比較して、遅延テストで83%大きな優位性を得ることができます。コツは、これらのビジュアルと能動的な想起を組み合わせることです。研究を深く探りたい方は、視覚学習テクニックに関する研究をご覧ください。
適切なツールは、この能動的なプロセスを楽に感じさせるように設計されています。HoverNotesのようなツールを使うと、気を散らさない動画モードで手動でノートを入力し、無料のスクリーンショット機能を使って、進みながら重要なビジュアルを即座にキャプチャできます。それらのノートを整理する方法についてより多くのアイデアを得たい方は、YouTubeの動画をノートに変換する方法のガイドをご覧ください。
すべてのビジュアル学習方法が同じではありません。受動的なテクニックは生産的に感じるかもしれませんが、能動的なテクニックが本当の学習が起こる場所です。
結論は明確です:脳にビジュアル情報で何かをすることを強制すればするほど、記憶する可能性が高くなります。目標は、単に見ることから、本当に理解することへ移行することです。
ビジュアルノートを取ることは素晴らしい第一歩ですが、その後どうなりますか?忘れられたフォルダに放置されていると、その価値を失います。目標は、実際に所有する、個人的で検索可能なナレッジベースを構築すること—学習セッションを永続的な資産に変えることです。
これは、ハードワークがロックインされる可能性のある独自のクラウドサービスから離れることです。そのため、多くの真剣な学習者はObsidianのようなローカルファーストツールに頼っています。ノートが自分のコンピューター上の単なるプレーンなMarkdownファイルであれば、知識は本当に将来に対応しています。ファイルを所有しています。移動し、バックアップし、grepできます—それらは単なるMarkdownです。
良いシステムは複雑である必要はありません。シンプルが通常は最良です。
自分にとって意味のある論理的なフォルダ構造から始めましょう—おそらくコースや科目ごとに整理します。次に、タグで別の検索可能性の層を追加します。ノートに#pythonや#calculusとタグ付けすると、異なる動画講義から関連するアイデアを簡単に引き出せます。
このシンプルなワークフロー—見る、スケッチする、説明する—が、受動的な視聴を能動的な学習に変えるものです。教材と直接関わることを強制され、そこで本当の理解が起こります。
最後のピースは点をつなげることです。ノートを孤立させたままにしないでください。特定のコーディング関数に関する新しいノートを、それが属するプログラミングパラダイムについてのより広いノートにリンクしてください。これにより、脳の働き方を反映した知識のウェブが構築され、見逃していたかもしれないつながりが作られます。
散らばったノートのコレクションが、あなたが管理する貴重な学習資産に変わります。それらは単なるファイルなので、サブスクリプションやプラットフォームのロックインなしに、永遠に所有できます。
他のツールを使っていますか?問題ありません。これらのノートはよくフォーマットされたMarkdownなので、ポータブルです。Notionのようなアプリに直接コピー&ペーストでき、すべての画像とフォーマットが完璧に一緒に来ます。
#質問がありますか?動画学習について話しましょう。
視覚型学習者が動画レッスンを定着させようとするときに直面する一般的な障害と、実践的なアドバイスをいくつか紹介します。
#「ノートを取るために常に一時停止と巻き戻しを繰り返すのをやめるにはどうすればいいですか?」
恐ろしい一時停止-再生-巻き戻しサイクルは集中力を殺し、20分の講義を1時間の試練に変える可能性があります。
シンプルな解決策は、画面の半分に動画、もう半分にノートという並べて表示するセットアップを使うことです。これは役立ちますが、すべての手動作業をまだ行っています。
より良い方法は、AIに最初の重労働を任せることです。HoverNotesのようなツールは、ノート取りアシスタントとして機能できます。一緒に「視聴」し、キーコンセプトを引き出し、タイムスタンプ付きスクリーンショットを自動的に取得するChrome拡張機能です。これにより、リアルタイムで教材を理解することに集中できます。後で、学習の流れを壊すことなく、AI生成のアウトラインに自分の考えを追加できます。
#「デジタルと物理的なマインドマップ、視覚学習にはどちらが良いですか?」
ホワイトボードや紙は、最初の雑然としたブレインストーミングに最適です。素早く、触覚的で、ソフトウェアに囚われることなく考えを出すことができます。
しかし長期的な学習には、デジタルマインドマップが画期的です。特にObsidian Canvasのようなものを使う場合は。動画の正確な瞬間に直接ジャンプするクリック可能なスクリーンショットを埋め込むことができます。概念をデジタルライブラリの他のノートにリンクし、シンプルなドラッグ&ドロップですべてを再配置できます。動画学習には、ビジュアルノートをソース資料に直接結び付けておくことができるため、デジタルアプローチがはるかに強力です。
#「ビジュアルノートを実際にレビューする最良の方法は何ですか?」
ノートをもう一度見るだけでは不十分です。情報を定着させる最良の方法は、能動的想起と間隔反復の組み合わせです。
マインドマップを受動的に再読するのではなく、テキストを隠して保存した図表を見てください。まるで誰かに教えているかのように、記憶から概念全体を声に出して説明してみてください。
タイムスタンプ付きスクリーンショットは強力な自己テストツールになります。ノートを隠し、画像を見て、説明します。次に、画像をクリックして動画に戻り、どれだけ正確だったかを確認します。これらのレビューセッションを間隔を空けて行うことで—おそらく1日後、3日後、1週間後—脳に情報を取り出すためにより懸命に働くことを強制し、持続的で長期的な記憶を構築します。
Obsidianユーザーにとって、動画ノートをクリーンなMarkdownファイルとしてVaultに直接保存できる機能は、ビジュアルナレッジベースの構築をほぼ楽にします。すべてを保管しているNotionにもノートはきれいにコピーできます。HoverNotesを無料で試すことができます—サインアップするだけで20分のAIクレジットがもらえ、クレジットカードは不要です。詳細と開始はこちら。
GeneralJanuary 11, 2026
Canvas、Blackboard、または大学のポータルで、キーとなるアイデアを素早く捉えるための実用的なシステムを使って、ビデオ講義からノートを取る方法をマスターしましょう。
GeneralJanuary 1, 2026
YouTube、Udemyなど、あらゆるプラットフォームのビデオでノートを取るための実践ガイド。記憶力を向上させ、忘れ物をなくすためのより良いワークフローを学びましょう。
GeneralFebruary 1, 2026
アクティブ・リコール、ノート術、効率的な学習ルーチンなど、科学的根拠に基づいた実証済みの戦略で、より速く学び、より多く記憶する方法を学びましょう。